In my earlier post, I had described a simplified view of how Word2Vec method uses neural learning to obtain vector representations for words given a large corpora. In this post I will describe another approach for generating high-dimensional representations of words via looking at co-occurrences of words. This method is claimed to be much faster as it avoids time consuming neural learning and yields comparable results.
Words Co-occurrence Statistics
Words co-occurrence statistics describes how words occur together that in turn captures the relationships between words. Words co-occurrence statistics is computed simply by counting how two or more words occur together in a given corpus. As an example of words co-occurrence, consider a corpus consisting of the following documents:
penny wise and pound foolish
a penny saved is a penny earned
Letting count(wnext|wcurrent) represent how many times word wnext follows the word wcurrent, we can summarize co-occurrence statistics for words “a” and “penny” as:
| a | and | earned | foolish | is | penny | pound | saved | wise | |
| a | 0 | 0 | 0 | 0 | 0 | 2 | 0 | 0 | 0 |
| penny | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 1 |
The above table shows that “a” is followed twice by “penny” while words “earned”, “saved”, and “wise” each follows “penny” once in our corpus. Thus, “earned” is one out of three times probable to appear after “penny.” The count shown above is called bigram frequency; it looks into only the next word from a current word. Given a corpus of N words, we need a table of size NxN to represent bigram frequencies of all possible word-pairs. Such a table is highly sparse as most frequencies are equal to zero. In practice, the co-occurrence counts are converted to probabilities. This results in row entries for each row adding up to one in the co-occurrence matrix.
The concept of looking into words co-occurrences can be extended in many ways. For example, we may count how many times a sequence of three words occurs together to generate trigram frequencies. We may even count how many times a pair of words occurs together in sentences irrespective of their positions in sentences. Such occurrences are called skip-bigram frequencies. Because of such variations in how co-occurrences are specified, these methods in general are known as n-gram methods. The term context window is often used to specify the co-occurrence relationship. For bigrams, the context window is asymmetrical one word long to the right of the current word in co-occurrence counting. For trigrams, it is asymmetrical and two words long. In words to vector conversion approach via co-occurrence, it turns out that a symmetrical context window looking at one preceding word and one following word for computing bigram frequencies gives better word vectors.
Hellinger Distance
Hellinger distance is a measure of similarity between two probability distributions. Given two discrete probability distributions P = (p1, . . . , pk) and Q = (q1, . . . , qk), the Hellinger distance H(P, Q) between the distributions is defined as:

Hellinger distance is a metric satisfying triangle inequality. The reason for including 
Word Vectors Generation
The approach in a nutshell is to create an initial vector representation for each word using the co-occurrences of a subset of words from the corpus. This subset of words is called context words. The initial vectors produced in this manner have dimensionality of few thousands with an underlying assumption that the meaning of each word can be captured through its co-occurrence pattern with context words. Next, a dimensionality reduction via principal component analysis (PCA) is carried out to generate final word vectors of low dimensionality, typically 50 or 100 dimensions. The diagram below outlines the different stages of the word vector generation process.

Starting with a given corpus, the first step is to build a dictionary. It is preferable to select only those lower case words for inclusion in the dictionary that occur beyond certain number of times. Also to deal with numbers, it is a good idea to replace all numbers with a special character string representing all numbers. This step generally leads to a manageable dictionary size, 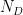
| earned | foolish | penny | saved | |
| a | 0 | 0 | 1 | 0 |
| penny | 1 | 0 | 0 | 1 |
A typical choice for context words is to choose top 5 to 10% most frequent words resulting in 
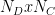
How good are Word Embeddings?
You can check how good is the above approach for word embedding by finding the top 10 nearest neighbors of a word that you can input at the following site:

For example, I got the following list of nearest neighbors for “baseball.” Pretty neat!

The approach briefly described above is not the only approach for word embeddings via co-occurrence statistics. There are few other methods as well as a website where you can compare the performance of different word embedding methods as well as make a two-dimensional mapping of a set of words based on their similarity. One such plot is shown below.

An Interesting Application of Word Embeddings
The work on word embeddings by several researchers has shown that word embeddings well capture word semantics giving rise to searches where concepts can be modified via adding or subtracting word vectors to obtain more meaningful results. One interesting application along these lines is being developed by Stitch Fix Technology for online shopping wherein the vector representations of merchandise is modified by word vectors of keywords to generate recommendations for customers as illustrated by the following example.

We can expect many more applications of word embeddings in near future as researchers try to integrate word vectors with similar representations for images, videos, and other digital artifacts.
